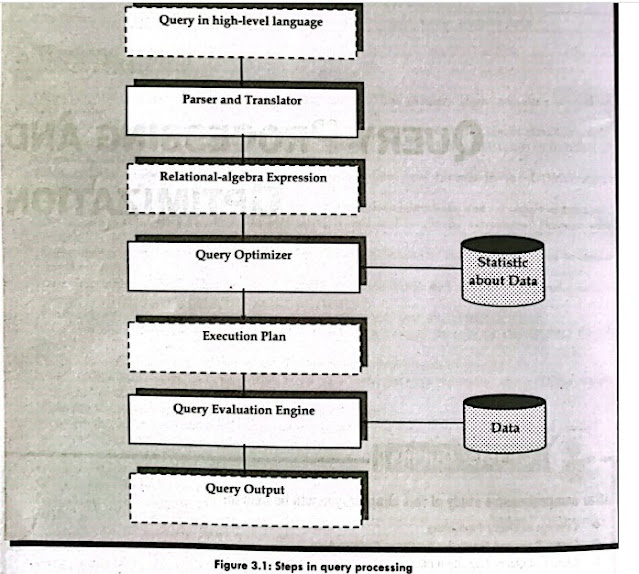
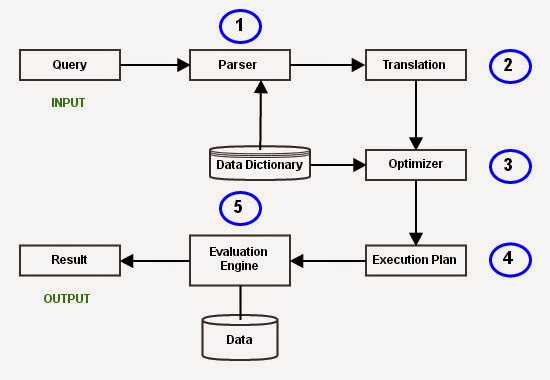
Define access path. Write the formula to calculate the cost of searching algorithm selections using indices.

A search algorithm that makes use of an index is called an index scan and the index structure is called an access path. An access path specifies the path chosen by a database management system to retrieve the requested tuples from a relation. The description of an externally described file contains the access path that describes how records are to be retrieved from the file. Records can be retrieved based on an arrival sequence (non-keyed) access path or on a keyed-sequence access path. OR, Access Path refers to the path chosen by the system to retrieve data after a structured query language (SQL) request is executed. A query may request at least one variable to be filled up with one value or more. The formula to calculate the cost of searching algorithm selections using indices A1 (primary index, equality on key): For an equality comparison on a key attribute with a primary index, we can use the index to retrieve a single record that satisfies the corresponding equali...


.png)
.gif)




.png)
.png)


.jpg)
.png)
.png)