Explain the text indexing techniques.
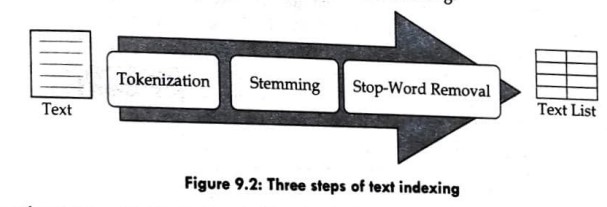
The three basic steps of text indexing are illustrated in figure 9.2. The first step is tokenization which is the process of segmenting a text by white spaces or punctuation marks into tokens. The second step is stemming which is the process of converting each token into its own root form using grammar rules. The last step is the stop-word removal which is the process of removing the grammatical words such as articles, conjunctions, and prepositions. Tokenization is the prerequisite for the next two steps, but the stemming and the stop-word removal may be swapped with each other, depending on the given situation.
1) Tokenization
Tokenization is defined as the process of segmenting a text or text into tokens by the white space or punctuation marks. It is able to apply tokenization to the source codes in C, C++, and Java, as well as the texts which are written in a natural language. However, the scope is restricted to only text in this study, in spite of the possibility. The morphological analysis is required for tokenizing texts which are written in oriental languages: Chinese, Japanese, and Korean. So, here, omitting the morphological analysis, we explain the process of tokenizing texts which are written in English.
Optional for writing point of view if asked explain process of tokenization then , only write all this that is the bracket
((
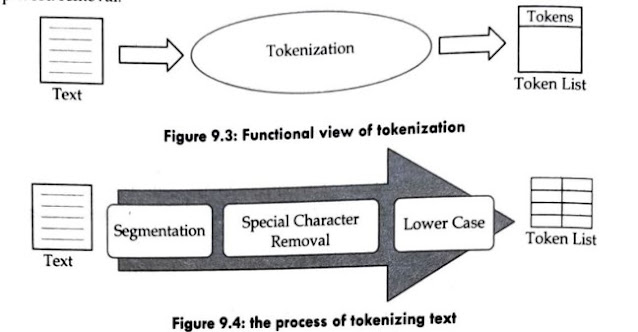
The functional view of tokenization is illustrated in figure 9.3. A text is given as the input, and the list of tokens is generated as the output in the process. The text is segmented into tokens by the white space or punctuation marks. As the subsequent processing, the words which include characters or numerical values are removed, and the tokens are changed into their lowercase characters. The list of tokens becomes the input of the next steps of text indexing: the stemming or the stop-word removal.
The process of tokenizing a text is shown in figure 9.4. The given text is partitioned into tokens by the white space, punctuation marks, and special characters. The words which include one or some of the special characters, such as "16%," are removed. The first character of each sentence is given as the uppercase character, so it should be changed into the lowercase. Redundant words should be removed after the steps of text indexing. ))

Figure 9.5: The example of tokenizing text
The example of tokenizing a text is illustrated in figure 9.5. In the example, the text consists of two sentences. Text is segmented into tokens by the white space, as illustrated on the right side in figure 9.3. The first word of the two sentences, "Text," is converted into "text," by the third tokenization step. In the example, all of the words have no special character, so the second step is passed.
2) Stemming
Stemming refers to the process of mapping each token that is generated from the previous step into its own root form. The stemming rules which are the association rules of tokens with their own root form are required for implementing it. Stemming is usually applicable to nouns, verbs, and adjectives, as shown in figure 9.6. The list of root forms is generated as the output of this step.

In the stemming, the nouns which are given in their plural form are converted into their singular form, as shown in figure 9.6. In order to convert it into its singular form, the character, “s," is removed from the noun in the regular cases. However, we need to consider some exceptional cases in the stemming process; for some nouns which end with the character, "s," such as "process," the postfix, "es," should be removed instead of "s," and the plural and singular forms are completely different from each other as the case of words, "child" and "children." Before stemming nouns, we need to classify words into nouns or not by the POS (Position of Speech) tagging. Here, we use the association rules of each noun with its own plural forms for implementing the stemming.
3)Stop-Word Removal
- Stop-word removal refers to the process of removing stop words from the list of tokens or stemmed words. Stop words are grammatical words that are irrelevant to text contents, so they need to be removed for more efficiency. The stop-word list is loaded from a file, and if they are registered in the list, they are removed. The stemming and the stop-word removal may be swapped; stop words are removed before stemming the tokens. Therefore, in this subsection, we provide a detailed description of stop words and the stop-word removal.
- The stop word refers to the word which functions only grammatically and is irrelevant to the given text contents. Prepositions, such as "in," "on," "to"; and so on, typically belong to the stop-word group. Conjunctions such as "and," "or," "but," and "however" also belong to the group. The definite article, "the," and the infinite articles, "a" and "an," are also more frequent stop words. The stop words occur dominantly in all texts in the collection; removing them causes to improve very much efficiency in processing texts.
- Let us explain the process of removing stop words in the ing. The stop-word list is prepared as a file and is loaded from it. For each word, if it is registered in the list, it is removed. The remaining words after removing stop words are usually nouns, verbs, and adjectives. Instead of loading the stop-word list from a file, we may consider using the classifier which decides whether each word is a stop word or not.



Comments
Post a Comment