Explain the different types of association rules with suitable example.
The popularity of association rule mining has led to its application on many types of data and application domains. Some specialized kinds of association rules have been reported in data mining literature. We describe here some of the important types:
1. Quantitative association rule: Quantitative association rules refer to a special type of association rule in the form of X-Y, with X and Y consisting of a set of numerical and/or categorical attributes. Different from general association rules where both the left-hand and the right-hand sides of the rule should be categorical attributes, at least one attribute of the quantitative association rule (left or right) must involve a numerical attribute. For example, Age (x, "30...39") salary (x. "42...48K") →buys(x, "car").
2. Boolean Association Rule: If a rule involves associations between the presence or absence of items, it is a Boolean association rule.
For example, buys(X, "laptop computer") → "HP printer"). buys(X,"HP_printer")
3. Single dimensional Association Rule: If the items or attributes in an association rule reference only one dimension, then it is a single-dimensional association rule.
For example, the rule buys(X, "computer") buys(X, "antivirus software") is single-dimensional association rule. Another example of single-dimensional association rule is buys(X, "Paper") → buys(X, "Pencil").
4. Multidimensional Association Rule: If a rule references two or more dimensions, such as the dimensions age, income, and buys, then it is a multidimensional association rule.
For example, age(X, "30...39") ^ income (X, "42K...48K") buys(X, "high resolution TV"). Based on whether a predicate is repeated or not there are two types of multidimensional association rule:-
a. Inter-dimension association rules: In this type of multidimensional association rule there is no repeated predicates. For example, age(X,"19-25") A occupation(X, "student") → buys(X, "Ruler").
b. Hybrid-dimension association rules: In this type of multidimensional association rule there is repeated predicates. For example, age(X,"19-25") buys(X, "popcom")→ buys(X, "Ruler").
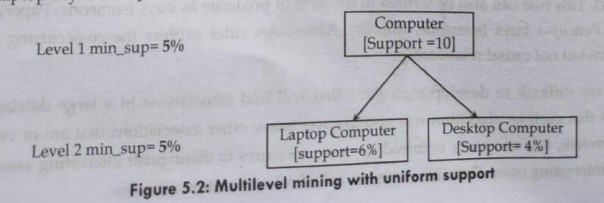
5. Multilevel Association Rule: Association rules generated from mining data at multiple levels of abstraction are called multilevel association rules. Multilevel association rules can be mined efficiently using concept hierarchies under a support-confidence framework. In general, a top-down strategy is employed, where counts are accumulated for the calculation of frequent itemsets at each concept level, starting at concept level 1 and working downward in the hierarchy toward the more specific concept levels, until no more itemsets can be found. For each level, any algorithm for discover frequent itemsets may be used, such as Apriori or its variations.
For example, First find high-level strong rules: Computer → keyboard [20%, 60% ]. Then find their lower-level "weaker" rules: "laptop computer" "laptop keyboard" [6%, 50% ].



Comments
Post a Comment