What do you mean by knowledge discovery in database (KDD)?
KNOWLEDGE DISCOVERY IN DATABASES (KDD)
Knowledge discovery in databases (KDD) is the process of discovering useful knowledge from a collection of data. This widely used data mining technique is a process that includes data preparation and selection, data cleansing, incorporating prior knowledge on data sets, and interpreting accurate solutions from the observed results. Major KDD application areas include marketing, fraud detection, telecommunication, and manufacturing. Data mining is the core part of the knowledge discovery process. KDP is a process of finding knowledge in data, it does this by using data mining methods (algorithms) in order to extract demanding knowledge from a large amount of data.
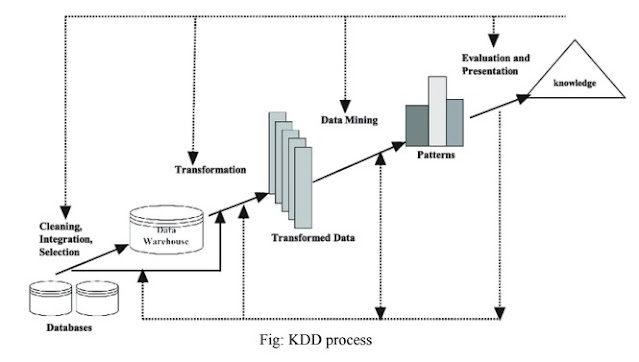
Simply stated, data mining refers to extracting or "mining" knowledge from large amounts of data stored in databases, data warehouses, or other information repositories. Many people treat data mining as a synonym for another popularly used term, Knowledge Discovery from Data, or KDD. Alternatively, others view data mining as simply an essential step in the process of knowledge discovery. Knowledge discovery consists of an iterative sequence of the following steps:

Data cleaning: The first step in the Knowledge Discovery Process is Data cleaning in which noise and inconsistent data are removed.
- Cleaning in case of Missing values.
- Cleaning noisy data, where noise is a random or variance error.
- Cleaning with Data discrepancy detection and Data transformation tools.
Data Integration: Data integration is defined as heterogeneous data from multiple sources combined in a common source(Data Warehouse).
- Data integration using Data Migration tools.
- Data integration using Data Synchronization tools.
- Data integration using ETL (Extract-Load-Transformation) process.
Data Selection: Data selection is defined as the process where data relevant to the analysis is decided and retrieved from the database.
- Data selection using neural network.
- Data selection using Decision Trees.
- Data selection using Naive bayes.
- Data selection using Clustering, Regression, etc.
- Data Mapping: Assigning elements from source base to destination to capture transformations.
- Code generation: Creation of the actual transformation program.
- Transforms task-relevant data into patterns.
- Decides purpose of the model using classification or characterization.
Pattern Evaluation: In Pattern Evaluation, data patterns are identified based on some interesting measures.
- Find interesting scores for each pattern.
- Uses summarization and Visualization to make data understandable by the user.
Knowledge Presentation: In Knowledge Presentation, knowledge is represented to the user using many knowledge representation techniques.
- Generate reports.
- Generate tables.
- Generate discriminant rules, classification rules, characterization rules, etc.
Knowledge discovery in databases (KDD) is the process of discovering useful knowledge from a collection of data. This widely used data mining technique is a process that includes data preparation and selection, data cleansing, incorporating prior knowledge on data sets, and interpreting accurate solutions from the observed results.
1. Identify the goal of the KDD process from the customer's perspective.
2. Understand application domains involved and the knowledge that's required
3. Select a target data set or a subset of data samples on which discovery is be performed.
4. Cleanse and preprocess data by deciding strategies to handle missing fields and alter the data as per the requirements.
5. Simplify the data sets by removing unwanted variables. Then, analyze useful features that can be used to represent the data, depending on the goal or task.
6. Match KDD goals with data mining methods to suggest hidden patterns.
7. Choose data mining algorithms to discover hidden patterns. This process includes deciding which models and parameters might be appropriate for the overall KDD process.
8. Search for patterns of interest in a particular representational form, which include classification rules or trees, regression, and clustering.
9. Interpret essential knowledge from the mined patterns.
10. Use the knowledge and incorporate it into another system for further action.
11. Document it and make reports for interested parties.


Comments
Post a Comment