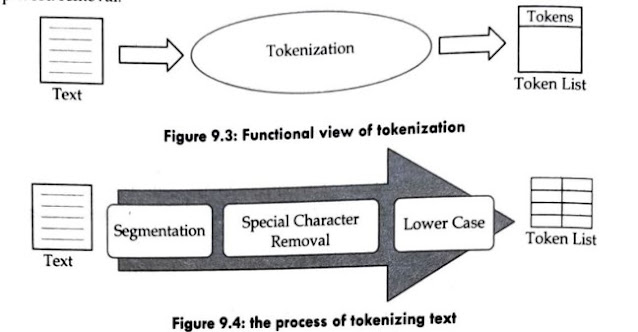
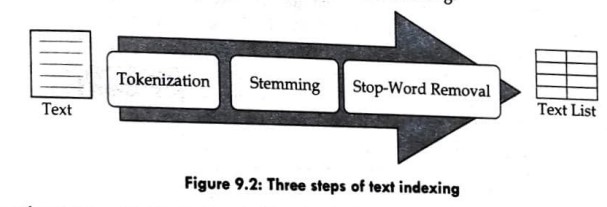
Short note on Stop Word Removal
Stop-Word Removal Stop-word removal refers to the process of removing stop words from the list of tokens or stemmed words. Stop words are grammatical words that are irrelevant to text contents, so they need to be removed for more efficiency. The stop-word list is loaded from a file, and if they are registered in the list, they are removed. The stemming and the stop-word removal may be swapped; stop words are removed before stemming the tokens. Therefore, in this subsection, we provide a detailed description of stop words and the stop-word removal. The stop word refers to the word which functions only grammatically and is irrelevant to the given text contents. Prepositions, such as "in," "on," "to"; and so on, typically belong to the stop-word group. Conjunctions such as "and," "or," "but," and "however" also belong to the group. The definite article, "the," and the infinite articles, "a" and ...